Pandas Group By and Join Operations

For the SQL minded like myself, Grouping, Aggregation and Joins in pandas can seem somewhat convoluted. The simplicity of performing these operations in SQL has spoilt us. But the underlying principles are the same. And with a little bit of brain friction, it's fairly straight forward to do the same in pandas.
In SQL, there is generally one way of doing things. In pandas, the same operation can be performed in multiple ways. Pandas makes a tradeoff of giving up some of the simplicity of SQL in favor of more complex syntax that allows greater flexibility.
Grouping and Aggregation
The dataset I'm working with is a set of transactions with Transaction Date, Currency.
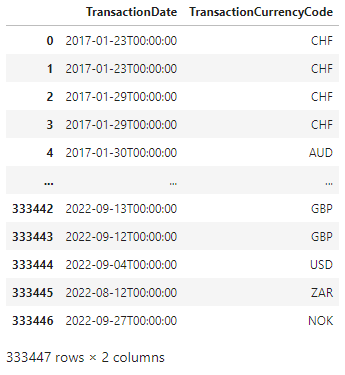
I want to get a dataset that provides the earliest and latest transaction dates in a currency and the total count of transactions in each currency.
In SQL, I'd write the following:
SELECT
TransactionCurrencyCode,
MIN(TransactionDate) as earliest,
MAX(TransactionDate) as latest,
COUNT(*) as count
FROM transactions
GROUP BY TransactionCurrencyCodeIn Pandas, we can get the same result like this:
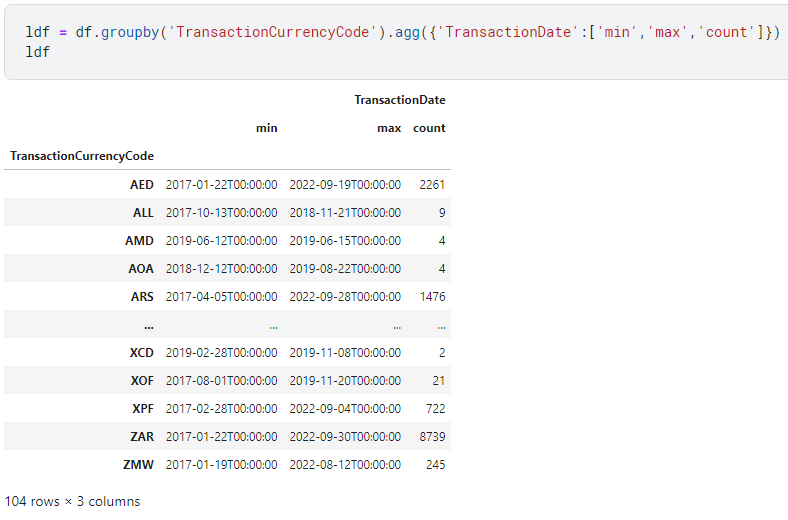
Notice that TransactionCurrencyCode is the Index for the DataFrame and TransactionDate is part of a Multilevel Index.
There's two things I'd like to change:
- I want the DataFrame to have single level index (similar to the kind of result I'd get in SQL). This is because of the JOIN operation I want to perform on this result.
- I don't want the columns to have generic names min, max and count.
I can get the flattened index columns like this:
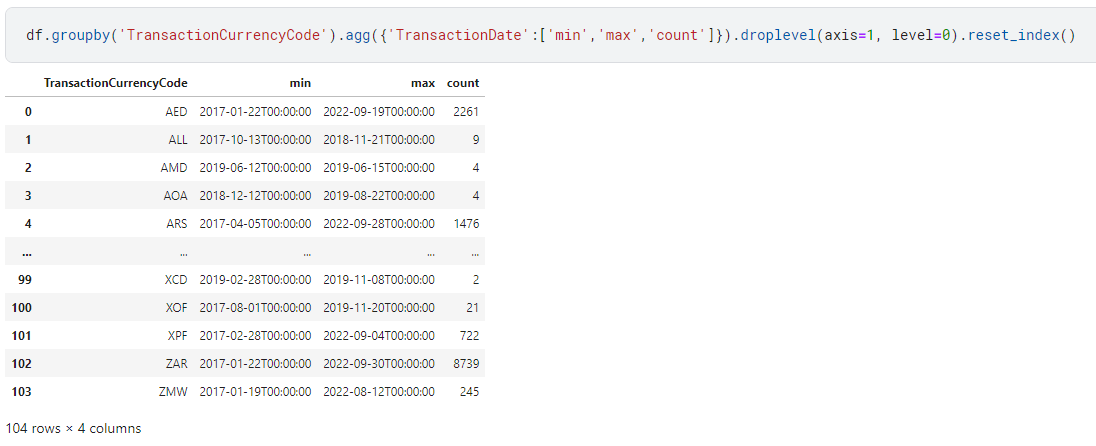
But there is another way to achieve this using a slightly more flexible syntax in the agg operation.
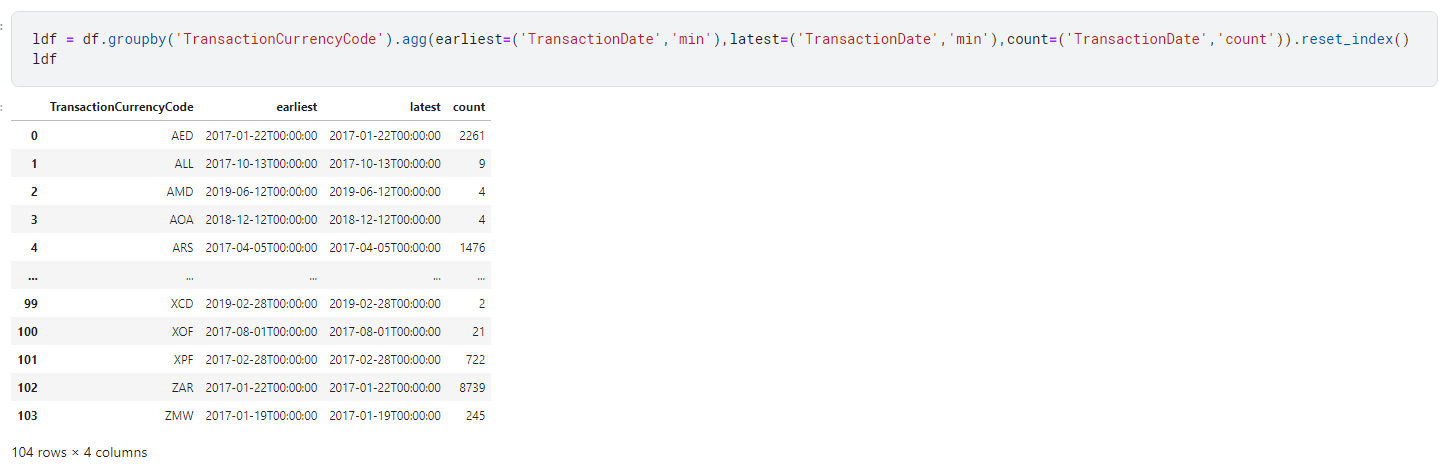
One important note in the above line of code. You have to write the operation in one line. If you split the aggregation and reset_index operations, you loose the TransactionCurrencyCode column in the join operations described below.
Joining
The next step I'd like to take is to join the result of the previous operations (which I'll store in a DataFrame variable ldf) to another frame that holds a list of currency codes (in a DataFrame variable rdf). For context, I'm performing this operation to determine if I have the currency data for all currency codes in ldf.
This is what rdf looks like:

This is how I perform the join operation between ldf and rdf
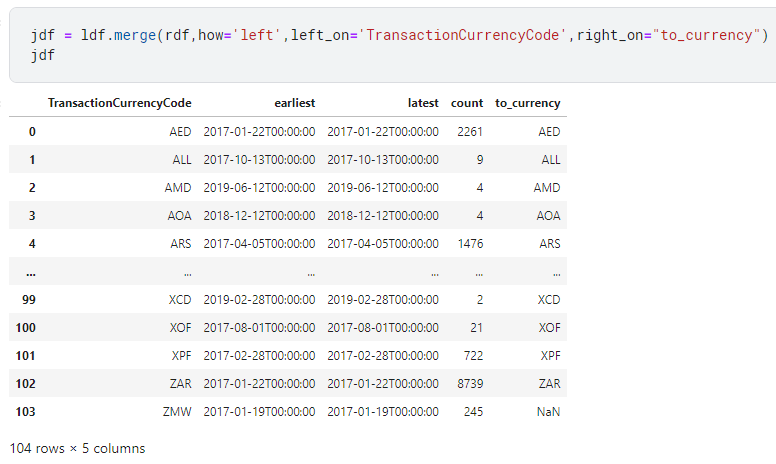
This is exactly how you perform a join in SQL. Only the syntax is different. The result is stored in a new DataFrame called jdf.
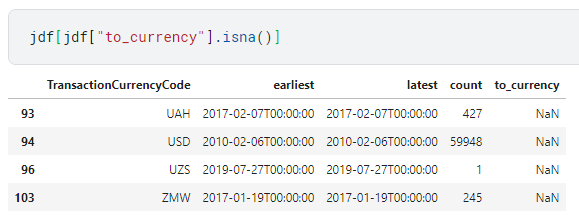
Now I'm going to identify which currencies are present in the left DataFrame which are not available in the right DataFrame.