Forget Excel. If you're going to do advanced analytics with blazing fast speeds, without the headache of installing, maintaining or obtaining access to a database server or a cloud based data warehouse, DuckDB is the way to go.
Most data analysts are not trying to do analytics at scale with humongous datasets. Any serious data scientist or analyst is going to have to learn SQL.
I know this is very opinionated. But I've played with dozens of data analytics tools over the last two decades. I always gravitate to using SQL. Because SQL is simple and robust. Whenever something is not easily expressive in SQL, I sprinkle a tinge of Python. The good thing about DuckDB is that it has an extremely seamless interface with Python, particularly with Pandas.
I've always felt that Pandas requires a lot more typing of code to achieve the same thing that could be done in SQL much more simply. For those types of use cases, it's now possible to run SQL queries directly on a Pandas DataFrame. Thanks again to DuckDB.
On a side note, I have developed a preference to using SQLite as my database of choice, even for OLTP applications. For most use cases, at the scale I operate, SQLite is amazing. It just wasn't very fast for analytics. DuckDB fills that void.
This is meant to be a living document where I will document the tips and tricks I learned with DuckDB.
Why Use DuckDB?
Even if you've got access to servers and cloud data warehouses, I still think DuckDB makes sense as a development tool.
Because of the speed of DuckDB and the fact that there's no network latency, you can execute the same query much faster than you would on a traditional database. I've done this myself and achieved 50x speed improvements. Complex queries packaged as a stored procedure that take 2 hours on the database server take 1 minute on DuckDB with Python as a procedural language.
During development, you can go through the iterations much faster and this impact compounds so that the feature you'd previously deliver in a week will now be in days and hours.
The other reason is cost. If you're working on cloud data warehouses, each iteration will cost you money. You can do most of the iterations locally, and once done, you can run your analytic on the cloud.
Comparing Dates and Date Strings in DuckDB
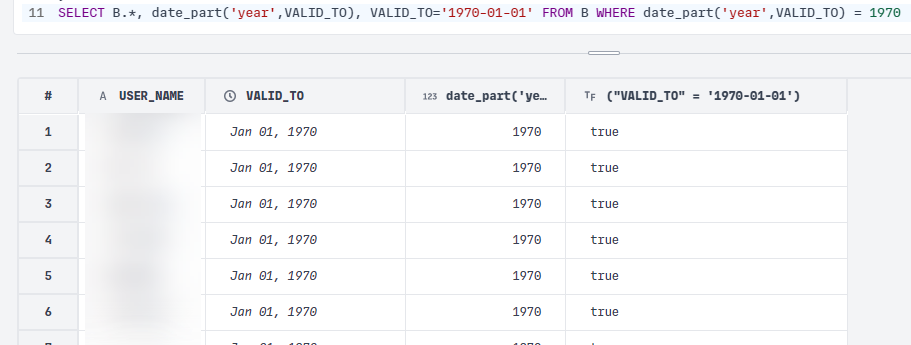
Most databases enforce strict data types, specially when comparing. One of the most notoriously problematic comparisons are dates. Sometimes dates are stored in string format, and would need to be converted to date type before any meaningful analysis can be performed.
However, with DuckDB, there appears to be common sense built in. In the dataset below, even though the dates are stored in string format "1970-01-01", they are automatically interpreted as dates when queried. However, if I compare it using a string e.g. VALID_TO='1970-01-01', it's correctly evaluated to true.
Query Column Names That Have Spaces
If you're querying a dataset with DuckDB that contains column names that have the space character in the column name, then you simply need to enclose the column name between double qoutes.
Here's an example of a query where I filter all results on a column named "Value to" where the values are not null.
Note that the column name is not case sensitive.

Using Short form SQL Statements
One of the nice features of DuckDB is that it has sensible defaults to save you from writing the same thing again and again.
Omit SELECT *
For example, typically, when you're exploring a dataset, you'll write SELECT * FROM table_name.
In DuckDB, if you want to select all columns, you could just omit the SELECT * part and just write FROM table_name. This will give you the same result as SELECT * FROM table_name.
GROUP BY ALL
Similarly, when we perform GROUP BY operations, we tend to repeat writing the same columns that we wrote in the SELECT part of the query.
For example, you might write SELECT Company, Division, Department, COUNT(*) FROM Employees GROUP BY Company, Division, Department.
This can be shortend by using GROUP BY ALL. The same statement as above could be written more concisely as follows: SELECT Company, Division, Department, COUNT(*) FROM Employees GROUP BY ALL.